- [Case Studies](/kategorie/case-studies)
- [E‑commerce tipy](/kategorie/e-commerce-tipy)
- [E‑shopové riešenia a platformy](/kategorie/e-shopove-riesenia-platformy)
- [Mergado Pack](/kategorie/mergado-pack)
- [Mergado tipy](/kategorie/mergado-tipy)
- [Novinky v Mergade](/kategorie/novinky-v-mergade)
- [Novinky z porovnávačov cien](/kategorie/novinky-z-porovnavacov-cien)
- [Pracujeme s Mergadom](/kategorie/pracujeme-s-mergadom)
- [Rozhovory](/kategorie/rozhovory)
- [Rozšírenia](/kategorie/aplikacie)
- [S Mergadom do zahraničia](/kategorie/s-mergadom-do-zahranicia)
- [Zo života Mergada](/kategorie/zo-zivota-mergada)
1. [ Domov ](/)
2. [ Blog ](/blog)
3. [ Case Studies ](/kategorie/case-studies)
4. **Ako pripraviť produktové dáta tak, aby dávali zmysel pre GPT Shopping?**
# **Ako pripraviť produktové dáta tak, aby dávali zmysel pre GPT Shopping?**
[  Alžběta Kocmanová ](https://www.mergado.cz/blog/alzbeta-kocmanova) [Case Studies](/kategorie/case-studies)
23. 4. 2026
9 minút čítania

V tejto prípadovej štúdii ukazujeme konkrétny postup, ako pracovať s **kontextom, produktovými popismi a ďalšími dátami** v Mergade tak, aby ich bolo možné efektívne využiť pri **generovaní obsahu pomocou jazykového modelu**.
function tableOfContents() {
return {
headings_menu: [],
heading_active: '', // Added to track the active section
shouldBeSticky: false,
generateToC() {
const headings = document.querySelectorAll('.js-article-full-headings h2, .js-article-full-headings h3');
let headingMap = {};
headings.forEach((heading) => { // Use an arrow function to maintain `this` context
// Normalize heading text to remove diacritics, then replace non-alphanumeric characters with dashes
var normalizedText = heading.textContent.normalize("NFD").replace(/[\u0300-\u036f]/g, ""); // Remove diacritics
var id = heading.id ? heading.id : normalizedText.trim().toLowerCase()
.split(' ').join('-').replace(/[^a-z0-9\-]/ig, ''); // Updated regex to replace non-alphanumeric characters
headingMap[id] = headingMap[id] !== undefined ? ++headingMap[id] : 0;
// Use the updated `id` with diacritics removed for the heading id and the TOC
const finalId = headingMap[id] ? `${id}-${headingMap[id]}` : id;
this.headings_menu.push({
id: finalId,
title: heading.textContent,
level: heading.tagName.toLowerCase(), // Track heading level
active: false, // Initially set active to false
});
heading.id = finalId;
});
},
checkStickyNeeded() {
const ul = this.$el.querySelector('ul');
if (ul) {
this.shouldBeSticky = ul.scrollHeight < window.innerHeight;
}
},
setActiveHeading() {
// disabled not working with active state on click
// add @scroll.window="setActiveHeading()" to the parent div
// const headings = document.querySelectorAll('.js-article-full-headings h2');
// let activeHeading = '';
// let closestHeadingDistance = Infinity;
// headings.forEach((heading) => {
// const rect = heading.getBoundingClientRect();
// const offset = rect.top - window.innerHeight / 2; // Consider heading in the middle of the screen as active
// if (offset < 0 && Math.abs(offset) < closestHeadingDistance) {
// activeHeading = heading.id;
// closestHeadingDistance = Math.abs(offset);
// }
// });
// // Update the active state in headings_menu
// if (activeHeading !== this.heading_active) {
// this.headings_menu = this.headings_menu.map(item => ({
// ...item,
// active: item.id === activeHeading,
// }));
// this.heading_active = activeHeading;
// }
},
setActiveItem(clickedId) {
this.headings_menu.forEach(item => {
item.active = (item.id === clickedId);
});
this.heading_active = clickedId; // Optionally update the heading_active property if used
},
};
}
1. —
## **📌 Úvod: O čom prípadová štúdia je**
GPT Shopping kladie na produktové dáta úplne iné nároky než klasické produktové kampane. Nestačí mať vyplnený popis produktu. Rozhodujúci je **kontext, relevancia a kvalita dát**, z ktorých jazykový model čerpá.
V tejto prípadovej štúdii ukazujeme **konkrétny postup optimalizácie produktových popisov a ďalších dát pre GPT Shopping**. Popisujeme, ako nad obsahom premýšľame v praxi, aké zdroje informácií využívame a ako ich pripravujeme tak, aby sa s nimi dalo efektívne pracovať.
Pracujeme s reálnym e‑shopom bežiacim na Shoptete (e‑shop [Dykka](https://dykka.com/)) a s nástrojom Mergado, ktorý slúži ako centrálne miesto na prípravu a správu dát. Nerobíme len samotné produktové popisy, ale aj ďalší obsah, ktorý má e‑shop k dispozícii, teda články, popisy kategórií, recenzie alebo informácie o značkách.
**Základný princíp je jednoduchý:**
👉 **kvalitný výstup pre GPT Shopping nevzniká z jedného textu, ale z dobre pripraveného kontextu.**
V ďalších kapitolách preto prejdeme jednotlivé typy obsahu, ich prípravu pre produktový feed a spôsob, ako ich následne využiť pri generovaní popisov pomocou jazykového modelu.
## **🗂️ Príprava dát pre kontext**
Pre GPT Shopping nestačí samotný popis produktu. Jazykový model pracuje **s kontextom, ktorý vzniká z rôznych zdrojov obsahu** naprieč e‑shopom.
Preto sme do optimalizácie zapojili viac typov informácií – **od článkov cez popisy kategórií až po recenzie alebo informácie o značkách**. V nasledujúcich kapitolách si ich prejdeme postupne a ukážeme, prečo dávajú zmysel.
## **📝 Články (interné aj externé)**
Články patrili medzi **najdôležitejšie zdroje kontextu**. Obsahujú informácie, ktoré sa do produktových popisov bežne nedostanú, no pre GPT Shopping majú vysokú hodnotu.
**Typicky ide o:**
- **spôsob použitia produktu v praxi,**
- konkrétne **scenáre a situácie**,
- hlavné **benefity a rozdiely**,
- informácie o tom, **pre koho je produkt určený** (persony).
Nie každý článok je však relevantný pre celý sortiment. Prvým krokom preto bolo **filtrovanie a segmentácia obsahu**, najčastejšie podľa kategórií alebo tém. Cieľom nebolo články kopírovať do feedu, ale **vybrať len to, čo dáva zmysel pre daný typ produktov**.
Popri vlastnom obsahu e‑shopu sme zohľadnili aj **externé články**. Tie sa hodia najmä pri produktoch, ktoré predáva viac e‑shopov, a môžu priniesť:
- iný uhol pohľadu,
- zrozumiteľnejšie vysvetlenie použitia,
- alebo doplňujúce informácie, ktoré na e‑shope chýbajú.
### **Ako sme články pripravili**
Aby sa dal obsah článkov efektívne použiť pri generovaní popisov, bolo potrebné ho najskôr pripraviť do vhodnej podoby.
Postupovali sme takto:
- z webu e‑shopu alebo zo **sitemapy** sme zozbierali relevantné URL adresy článkov,

Ak chcete jazykovému modelu posielať len čistý text bez zbytočných prvkov, môžete články stiahnuť pomocou rozšírenia Mergada [Scraping Camel](https://store.mergado.com/detail/scrapingcamel/?lang=cs#about), vďaka ktorému vytiahnete z vlastného webu len samotný text bez ďalšieho balastu.
- URL adresy článkov sme nahrali do **NotebookLM**,
- pre každú kategóriu sme si nechali vygenerovať **stručné zhrnutie relevantného obsahu**,
- výsledné zhrnutia sme uložili **do samostatných Markdown súborov**.

**Prečo Markdown?** Markdown je dobre čitateľný pre LLM a zároveň s ním vedia pracovať rozšírenia ako [Mergado Files](https://store.mergado.com/detail/files/#about) alebo [Mergado Contexts](https://store.mergado.com/detail/mergadocontexts/#about).
### **Ako sme obsah využili v Mergade**
Hotové zhrnutia sme:
- nahrali do rozšírenia [**Mergado** **Files**](https://store.mergado.com/detail/files/#about),
- ako alternatívu môžete použiť aj rozšírenie [**Mergado** **Context**](https://store.mergado.com/detail/mergadocontexts/#about),
- sprístupnili cez **URL adresy**,
- a využívali ich **priamo v prompte** pri generovaní popisov.
Tento obsah sa **neexportoval do finálneho feedu**. Slúžil čisto ako doplnkový kontext pre jazykový model, ktorý mal vďaka tomu k dispozícii správne informácie v správny moment.
## **📋 Popisy kategórií**
Popisy kategórií sme použili ako **širší kontext nad rámec jednotlivých produktov**. Zatiaľ čo produktový popis rieši konkrétne vlastnosti a benefity, popis kategórie pomáha jazykovému modelu pochopiť:
- aký typ produktov do kategórie patrí,
- aké sú medzi nimi rozdiely alebo alternatívy,
- aký problém alebo potrebu daná kategória všeobecne rieši.
Tieto informácie sa hodia najmä v situáciách, keď samotný produktový popis nestačí alebo je príliš stručný.
### **Ako sme popisy kategórií pripravili**
Keďže e‑shop beží na Shoptete, využili sme ako primárny zdroj dát **feed kategórií zo** **Shoptet****u**.
Postup bol nasledujúci:
- feed kategórií sme nahrali do **pomocného projektu v** **Mergade**,
- v projekte sme upravili výstup tak, aby sme získali:
- názov kategórie,
- zodpovedajúci popis kategórie,
- výstup sme exportovali do **CSV súboru**,
- pomocou pravidla **Import dátového súboru** sme CSV nahrali späť do produktového feedu,
- popis kategórie sme ku každému produktu priradili pomocou **párovacieho elementu s názvom kategórie**.
Takto pripravený obsah sme ukladali do **pomocného elementu**. Ten sa nemusel exportovať do finálneho feedu, ale slúžil ako ďalší zdroj kontextu, s ktorým sme pracovali priamo v prompte.
## **🛒 Všeobecné informácie o e‑shope**
Ďalším zdrojom kontextu boli **všeobecné informácie o e‑shope.** Nejde o dáta vzťahujúce sa ku konkrétnemu produktu, ale o rámec, v ktorom sa celý sortiment pohybuje.
Tieto informácie pomáhajú jazykovému modelu lepšie pochopiť:
- čo e‑shop predáva a na čo sa špecializuje,
- kto je cieľová skupina a aké sú hlavné persony,
- aké hodnoty, víziu alebo smerovanie e‑shop má,
- a prípadné špecifiká sortimentu (napr. varianty produktov, špecifické typy tovaru).
Súčasťou tohto kontextu môžu byť aj všeobecné informácie o doprave, vrátení tovaru alebo ďalších pravidlách, ak sú relevantné pre výslednú podobu popisov.
### **Ako sme informácie o e‑shope pripravili**
Príprava týchto dát bola oproti iným zdrojom relatívne jednoduchá.
Postupovali sme takto:
- pomocou jazykového modelu (napr. OpenAI ChatGPT) sme si nechali pripraviť **všeobecný popis e‑shopu**,
- ako vstup sme zadali názov e‑shopu a jeho URL adresu,
- výsledný text sme uložili do **Markdown súboru**,
- súbor sme sprístupnili cez [**Mergado** **Files**](https://store.mergado.com/detail/files/#about).
Rovnako ako pri článkoch sa tento obsah **neukladal ku každému produktu zvlášť**. Slúžil ako **globálny kontext**, ktorý sme do promptu pridávali len tam, kde to dávalo zmysel.
## **⭐ Recenzie produktov**
[ 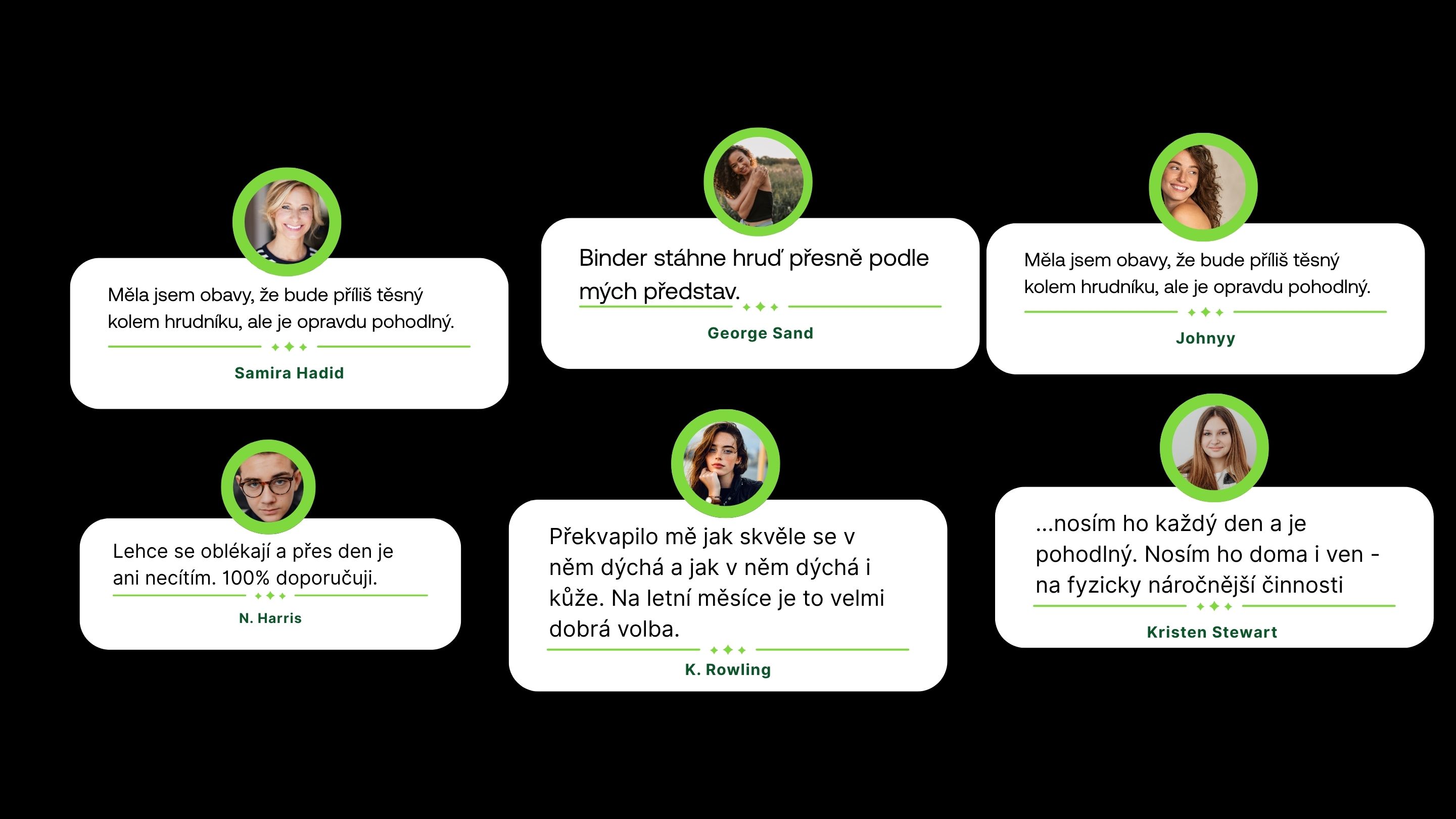 ](https://www.mergado.sk/sites/default/files/perm/image/recenze_casestudy_gptshopping.jpg)
Recenzie produktov patrili medzi **najcennejšie zdroje informácií**, no zároveň predstavovali **najväčšiu výzvu z pohľadu prípravy dát**. Na rozdiel od článkov alebo popisov kategórií totiž nie sú prirodzene štruktúrované na prácu na úrovni produktu.
Ich hlavný prínos je však jasný:
- obsahujú **reálne skúsenosti zákazníkov**,
- opisujú **praktické použitie v bežnom živote**,
- upozorňujú na **detaily, na ktoré si dať pozor**,
- a často odpovedajú na otázky, ktoré sa bežne objavujú v Q&A.
Práve preto sú recenzie veľmi silným zdrojom kontextu pre GPT Shopping.
### **Hlavná výzva: jedna recenzia ≠ jeden produkt**
Recenzie sú typicky vedené tak, že:
- každá recenzia je samostatná položka,
- jeden produkt sa v dátach objavuje opakovane,
- dáta nie sú pripravené na úrovni produktu, ale jednotlivých hodnotení.
Pre naše potreby sme však potrebovali dostať **všetky recenzie týkajúce sa jedného produktu k danému produktu vo feede**. To znamenalo recenzie deduplikovať, zlúčiť a doplniť o súhrnné metriky.
### **Ako sme recenzie pripravili**
Zvolili sme cestu **úpravy dát mimo** **Mergado** **a ich následný import**.
Postup bol nasledujúci:
- recenzie sme stiahli z administrácie Shoptetu do **CSV súboru**,
- dáta sme otvorili v **Google** **Sheets,**
- pomocou funkcií:
- UNIQUE sme recenzie **deduplikovali**,
- TEXTJOIN sme **zlúčili texty recenzií ku konkrétnemu produktu**,
- zároveň sme spracovali aj číselné hodnoty:
- jednotlivé hodnotenia,
- priemerné hodnotenie,
- počet recenzií,
- výslednú tabuľku sme zverejnili ako **CSV**,
- pomocou pravidla **Import dátového súboru** sme dáta nahrali späť do produktového feedu,
- recenzie a hodnotenia sme ukladali do **pomocných elementov** (napr. product\_reviews, product\_rating).
Tieto elementy potom slúžili ako ďalší vstup pre prompt pri generovaní popisov.
### **Alternatívny postup**
Vyskúšali sme aj alternatívne riešenie založené na **recenzných feedoch** z Google alebo Heureka.
Postup bol zložitejší:
- vytvorili sme **dva pomocné projekty v** **Mergado**,
- dáta sme previedli do **Shoptet** **dodávateľského XML formátu**,
- využili sme **zlučovanie variantov**, aby sa produkt vyskytoval iba raz,
- recenzie zostali zachované ako varianty,
- následne sme dáta previedli do CSV a importovali do produktového feedu.
Tento postup je funkčný, ale náročnejší na nastavenie a údržbu.
## **🏷️ Popisy značiek**
Popisy značiek sme využili ako **doplnkový zdroj kontextu**, ktorý pomáha jazykovému modelu lepšie pochopiť, **kto za produktom stojí** a v akom rámci sa pohybuje.
Ich prínos je predovšetkým v tom, že:
- dopĺňajú informácie o výrobcovi,
- naznačujú špecializáciu alebo zameranie značky,
- môžu pridať kontext k hodnotám alebo kvalite produktov.
Nejde o kľúčový zdroj pre každý produkt, no v kombinácii s ďalšími dátami pomáha dotvoriť celkový obraz.
### **Ako sme popisy značiek pripravili**
Využili sme to, že Shoptet umožňuje **export značiek do CSV**.
Postup bol nasledujúci:
- export značiek sme nahrali do **jednoduchého projektu v** **Mergado**,
- v projekte sme upravili štruktúru dát tak, aby sme získali:
- názov značky ako párovací prvok,
- popis značky ako hodnotu,
- výsledné CSV sme pomocou pravidla **Import dátového súboru** nahrali do produktového feedu,
- popisy značiek sme k produktom priradili **podľa názvu značky.**
Rovnako ako pri ostatných zdrojoch sme tento obsah ukladali do **pomocných elementov**. Tie slúžili ako ďalšie vstupné dáta pre prompt, nie ako obsah určený priamo do výstupného feedu.
## **🤖 Optimalizácia produktových popisov pomocou GPT**
[  ](https://www.mergado.sk/sites/default/files/perm/image/casestudy_gptshopping.png)
Akonáhle sme mali všetky zdroje obsahu pripravené – či už uložené v Markdown súboroch cez[ Mergado Files,](https://store.mergado.com/detail/files/#about) alebo importované do produktového feedu ako pomocné elementy – prišla na rad samotná **optimalizácia produktových popisov pomocou jazykového modelu**.
Cieľom už nebolo dáta len zhromaždiť, ale **aktívne ich využiť pri generovaní obsahu**, ktorý je:
- kontextovo bohatší,
- relevantnejší pre GPT Shopping,
- a zároveň konzistentný naprieč celým sortimentom.
Pro tuto část jsme využili rozšíření [**Mergado Sources**](https://store.mergado.com/detail/clickinggoat/), které umožňuje pracovat s GPT modely přímo nad daty v Mergadu.
### **Použitý nástroj a jeho rola**
Rozšírenie [Mergado Sources](https://store.mergado.com/detail/clickinggoat/#about) slúži ako prepojenie medzi dátami v Mergade a jazykovým modelom. Umožňuje:
- definovať, **z akých elementov a zdrojov má model čerpať**,
- pracovať s výbermi produktov,
- zapisovať výstupy priamo späť do feedu.
Vďaka tomu je možné generovanie popisov automatizovať a riadiť ho pomocou rovnakých princípov, aké sa v Mergade používajú aj pri iných úpravách dát.
### **Postup krok za krokom**
Samotný proces optimalizácie sme rozdelili do niekoľkých jasných krokov. Vďaka tomu sa dal celý postup dobre testovať, ladiť a postupne škálovať.
Postupovali sme takto:
1. **Aktivovali sme rozšírenie Mergado Sources**
Rozšírenie sme prepojili s OpenAI pomocou API tokenu získaného z účtu na platform.openai.com.
2. **Vytvorili sme nový element**
Na stránke *Elementy* sme vytvorili nový element, do ktorého sa mal zapisovať výstup z jazykového modelu.
3. **Zvolili sme zdroj dát**
Ako zdroj sme vybrali OpenAI a priradili výber produktov, nad ktorými sa mal obsah generovať.
4. **Zvolili sme výber produktov**
👉 **Tip**: Odporúčame začať na malej vzorke produktov, ideálne na jednom produkte. Testovanie je rýchlejšie a zbytočne sa nemíňajú tokeny.
5. **Zadali sme prompt**
Prompt sme zadávali ručne a snažili sa byť čo najkonkrétnejší:
- aký je cieľ výstupu,
- ako má výsledný popis vyzerať,
- akú má mať štruktúru,
- z akých zdrojov má model čerpať.
[  ](https://www.mergado.sk/sites/default/files/perm/image/screenshot_prompt_gpt-shopping.png)
6. **Pomocou premenných sme do promptu zapojili:**
- popisy kategórií,
- popisy značiek,
- recenzie produktov,
- všeobecné informácie o e‑shope,
- prípadne odkazy na Markdown súbory z [Mergado Files](https://store.mergado.com/detail/files/).
**Celé znenie použitého promptu nájdete tu 👇**
[Kompletný prompt](https://drive.google.com/file/d/1Lmg1vOjrlPILReXCcvyiUXI0LB6QNeJy/view)
7. **Nastavili sme parametre modelu**
- mieru kreativity (temperature) sme ponechali na hodnote 0,5,
- testovali sme rôzne modely (napr. GPT‑5, GPT‑5 Mini, GPT‑5 Nano).
👉 Konkrétny model odporúčame vždy **otestovať – výsledky sa môžu líšiť podľa typu sortimentu**.
8. **Zvolili sme cieľový element**
Výstup sme zapisovali buď:
- do nového elementu,
- alebo priamo do existujúceho elementu (napr. pole Description v GPT Shopping feede).
9. **Otestovali sme ukážkový výstup**
Rozšírenie umožňuje vygenerovať **náhľad výstupu pre náhodný produkt**, čo je veľmi užitočné pri ladení promptu.
10. **Aplikovali sme pravidlá**
Je potrebné počítať s tým, že pravidlá sa aplikujú dvakrát,
1. prvýkrát sa dáta odošlú do OpenAI API,
2. druhýkrát sa vrátený výstup zapíše do cieľového elementu.
👉 Medzi oboma krokmi je vhodné nechať **časovú rezervu**, pretože spracovanie môže trvať aj desiatky minút v závislosti od množstva dát.
### **Kontrola výsledkov a ďalšie možnosti**
Po vygenerovaní popisov sme:
- kontrolovali výsledný obsah pri produktoch,
- ďalej ladili samotný prompt,
- overovali konzistentnosť naprieč sortimentom.
Rovnaký prístup je možné použiť aj na **optimalizáciu produktových názvov**. Zdroje dát sú už pripravené, takže postup je veľmi podobný ako pri popisoch.
## **🏁 Záver**
V tejto prípadovej štúdii sme ukázali, **ako je možné pomocou Mergada systematicky optimalizovať produktové popisy a ďalšie dáta pre GPT Shopping**. Nešlo len o samotné generovanie textov, ale predovšetkým o prácu s kontextom a relevanciou. Teda o to, **aké dáta jazykovému modelu odovzdáme a v akej podobe**.
Opísaný postup je síce založený na konkrétnom e‑shope a konkrétnom technickom riešení, no je **dostatočne univerzálny** na to, aby sa dal aplikovať aj na iné projekty. Kľúčové je pochopiť logiku:
- vybrať relevantné zdroje obsahu,
- pripraviť ich do štruktúrovanej podoby,
- cieľene ich využiť pri práci s jazykovým modelom.
Ak sa rozhodnete tento prístup vyskúšať aj pri svojom e‑shope, odporúčame začať postupne. Testovať na menšej vzorke produktov, ladiť prompt a až potom riešenie škálovať na celý sortiment.
Budeme radi, keď sa s nami podelíte o svoje skúsenosti – ako sa vám postup osvedčil, či priniesol očakávané výsledky a prípadne aké ďalšie zjednodušenie alebo vylepšenie ste pri práci objavili. Držíme palce. 💪
- [ ChatGPT Shopping ](/tema/chatgpt-shopping)
[  ](https://www.mergado.cz/blog/alzbeta-kocmanova)### [ Alžběta Kocmanová ](https://www.mergado.cz/blog/alzbeta-kocmanova)
Copywriterka a obsahová specialistka Alžběta spojuje své dovednosti v psaní s vášní pro žurnalistiku a sociologii, které studuje. Ve své práci se zaměřuje na vytváření kvalitního obsahu a komunikaci, která rezonuje s cílovým publikem. Když není v práci nebo ve škole, věnuje se tanci, józe nebo tráví čas se svou kočkou, která ji vždycky drží v pozoru.
## Mohlo by vás *zaujímať*
[ 
### Ako optimalizácia feedu zvýšila výkon Meta Ads bez navýšenia rozpočtu
](/blog/optimalizace-feedu-pro-Meta-Ads)
[ 
### Reálny dopad vizuálnej úpravy produktových obrázkov na výkon Meta kampaní
](/blog/vizualy-pre-meta-kampane)
[ 
### Ako sme s Mergadom previedli e‑shop zo Shoptetu na Shopify: kompletná migrácia bez straty dát
](/blog/ako-sme-s-mergadom-previedli-e-shop-zo-shoptetu-na-shopify-kompletna-migracia-bez-straty-dat)
## Nenechajte si nič *ujsť*
Prihláste sa k odberu nášho newslettera
Prihlásením súhlasíte s tým, že vaše údaje budeme spracovávať v súlade s našimi [zásadami ochrany osobných údajov](/vyhlasenie-o-cookies).
Ďakujeme, úspešne ste sa pripojili k nášmu zoznamu odberateľov.
function ml_webform_success_5807248() {
var r = ml_jQuery || jQuery
r('.ml-subscribe-form-5807248 .row-success').show(), r('.ml-subscribe-form-5807248 .row-form').hide()
}